Slit smearing in Irena¶
Slit smearing is built into Irena and is handled transparently in most tools, with the following exceptions:
Guinier-Porod model — slit smearing is not supported and has been disabled in this tool. Setup with slit-smeared data and local fits is impractical.
Unified Fit — slit smearing is supported, but local fits (primarily the power-law fit) return pinhole-equivalent values, which can be confusing.
Modeling — slit smearing works correctly, but Unified level local fits also return pinhole equivalents.
Smearing in Irena approximates the APS USAXS instrument geometry: a rectangular one-dimensional slit with negligible slit width (typically 0.00008 Å-1) and a slit length that dominates the smearing. When the slit width is very small relative to the slit length, the geometry is well approximated by a purely 1D-slit-smeared model with only the slit length as a parameter.
This approach has been verified by comparing slit-smeared and 2D-collimated USAXS measurements from the same sample. When slit smearing has been suspected as the cause of artifacts or unexpected results, other sources have consistently been found. Since desmearing always increases data noise, it is generally preferable to fit slit-smeared data directly with slit smearing built into the model, rather than desmearing the data.
Note
Slit smearing and desmearing assume isotropic scattering. For anisotropic samples, slit-smeared instruments and slit-smeared data analysis are strongly discouraged.

The figure (from J. Appl. Cryst. 42, 469–479, 2009, doi:10.1107/S0021889809008802) defines the slit geometry used in this manual. Smearing arises from:
Finite slit length — perpendicular to the high-Q resolution direction (perpendicular to the vertical Q direction in the figure). The total detector horizontal opening is 2 × slit length.
Finite slit width — perpendicular to the Q direction, given by the detector/instrument geometry. The total detector opening in the Q direction is 2 × slit width.
Note
Slit length is not Q-resolution. Slit width could be considered an approximation for Q-resolution, but the final data Q-resolution (from Indra and Nika, reported as dQ) also reflects data processing and binning effects and can be significantly worse than the raw slit width. Do not confuse slit width and dQ.
Desmearing¶
The desmearing routine uses the Lake method (reference), originally implemented by Pete Jemian and adapted for Igor Pro. The method has been verified repeatedly by comparing desmeared data to 2D-collimated USAXS measurements from the same sample. When desmearing was suspected as the source of artifacts, other causes were consistently found.
The desmearing tool supports both slit length (perpendicular to Q) and slit width (parallel to Q). The slit shape can be trapezoidal (as in GNOM):

The height of the trapezoid is the slit width.
Note
Irena desmearing parameters are ½ of the corresponding GNOM parameters. If you have GNOM parameters, divide them by 2 before entering them here.
Parameter notes:
Setting slit length or slit width to 0 assumes infinite resolution in that direction.
Setting the L parameter to 0 assumes a rectangular (non-trapezoidal) slit shape.
Example of the desmearing procedure¶
A sample slit-smeared dataset is included in the Irena distribution
(smeared data.dat, slit length = 0.05113 Å-1). Import it using the
Data import tool as QRS data.
Note
Clicking on any tab to the left of the current tab returns to that step, discarding all steps to the right. Smoothing parameters that are enabled (checkboxes checked) are applied even if the smoothing tab was not explicitly visited.
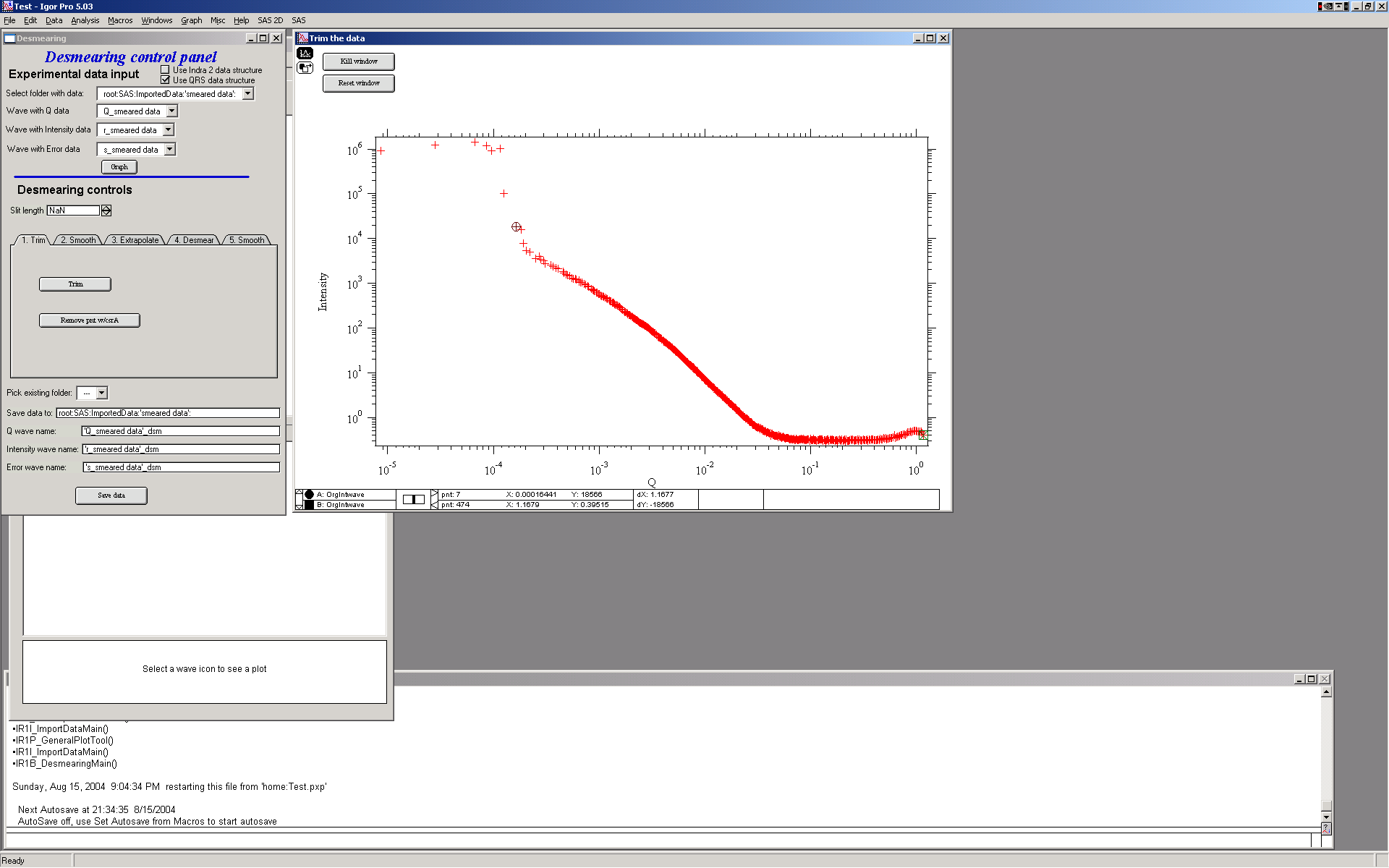
After loading, enter the slit length. The tabs must be worked through left to right for each dataset.
Step 1 — Trim data
Use cursors to define the usable Q range, then click “Trim”. Remove isolated spurious points with the secondary button and cursor A (round cursor).

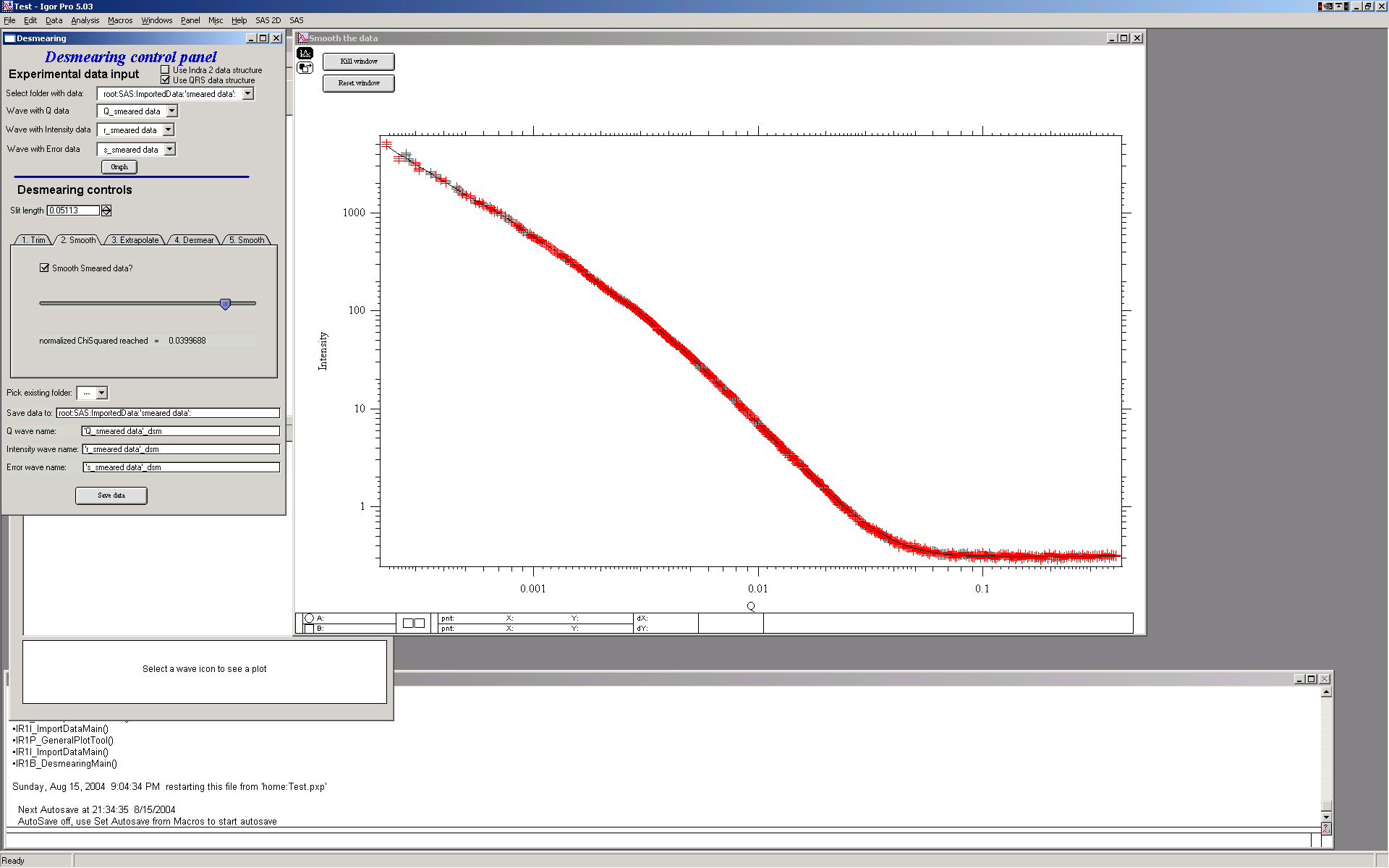
Step 2 — Optional smoothing (not recommended)
Spline smoothing is available but is generally discouraged at this stage. If used, the slider controls the smoothing intensity — further right means more smoothing.
Step 3 — Extrapolation
Desmearing requires data extending at least one slit length beyond the last measured point. Extrapolate using one of the available functions. For most SAXS data, “Power law with flat” or “Power law” is appropriate.
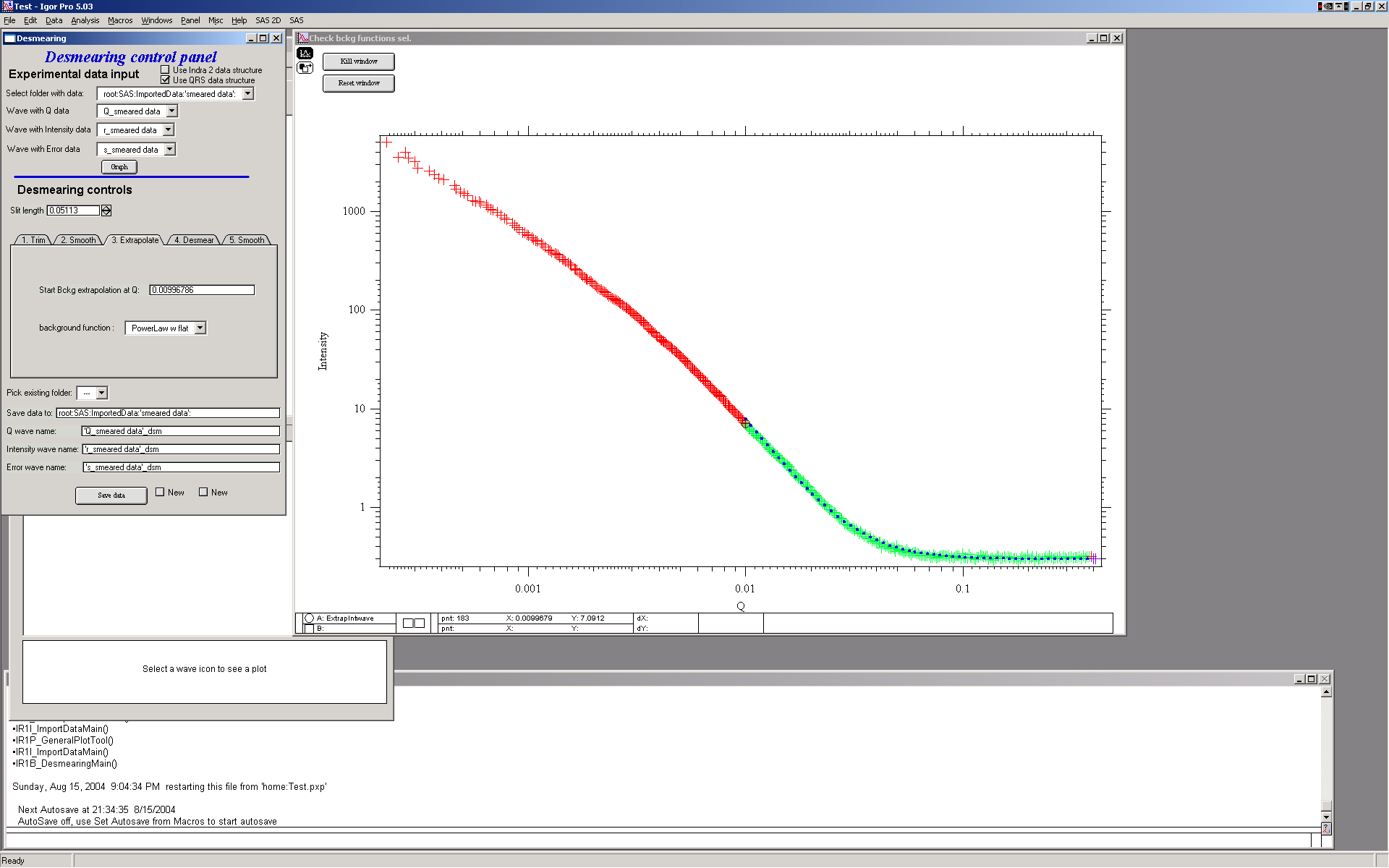
Colors: red = original data; green = data used for fitting the extrapolation; blue dotted = extrapolated data.
Step 4 — Desmearing
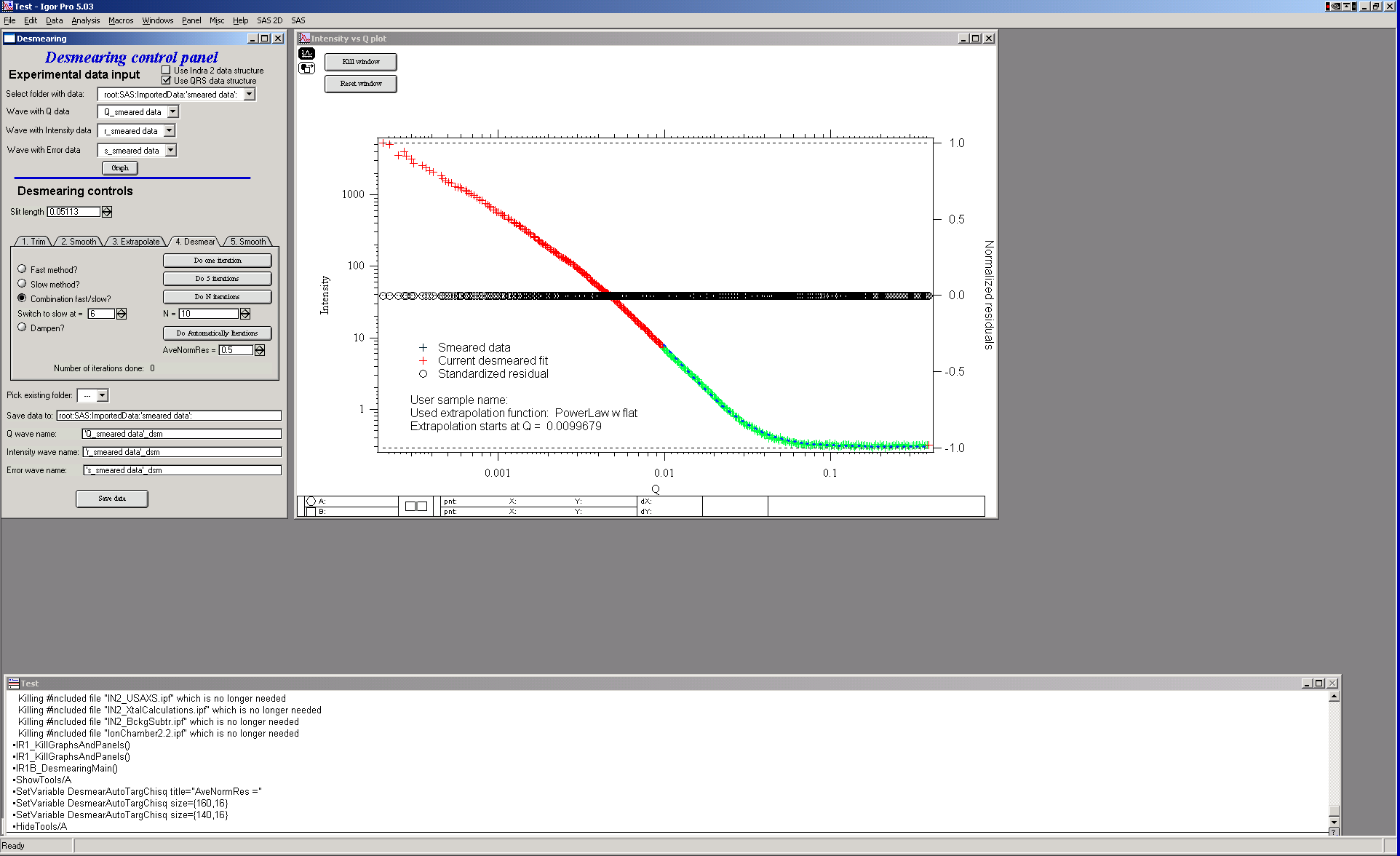
Several desmearing modes are available:
One iteration at a time, 5 at a time, or a user-specified number.
Automatic — iterates until the average normalized residual falls below a preset threshold.
Fast method — the recommended general-purpose method.
Slow method — converges more slowly and can produce negative intensities.
Combination — uses the fast method as the primary but switches to the slow method for individual points where the normalized residual falls below a user-specified threshold.
Dampen — uses the fast method but stops desmearing individual points once their normalized residual falls below 0.5.
The Combination and Dampen modes reduce high-Q noise from large iteration counts while preserving fast convergence.
After one iteration:
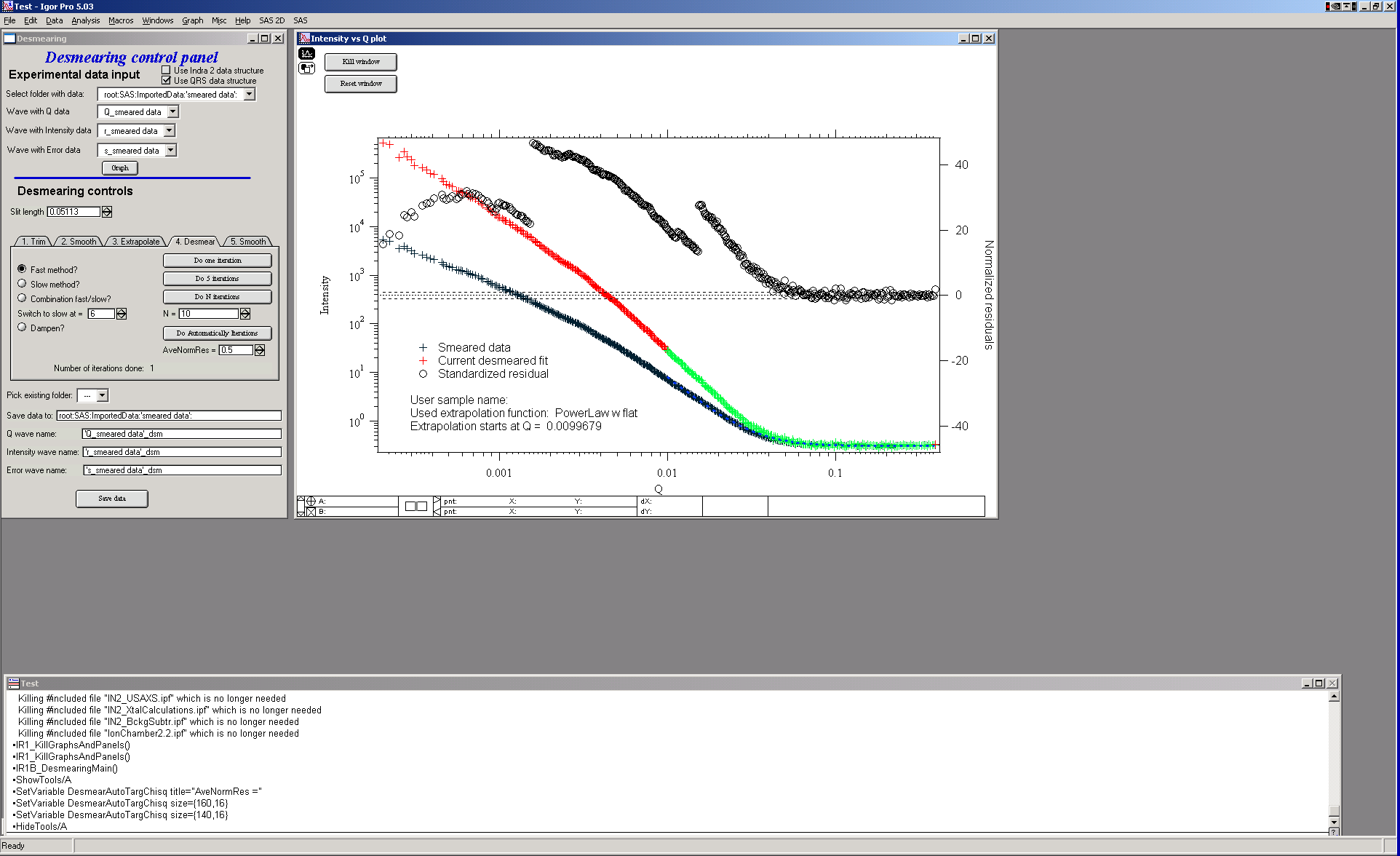
Red/green data: current desmeared result. Crosses: original slit-smeared data. Circles: normalized residuals.
Continue desmearing until the normalized residuals are randomly distributed around zero with no systematic trend. Convergence is assessed by the user — successive iterations should produce negligible changes in the residuals.
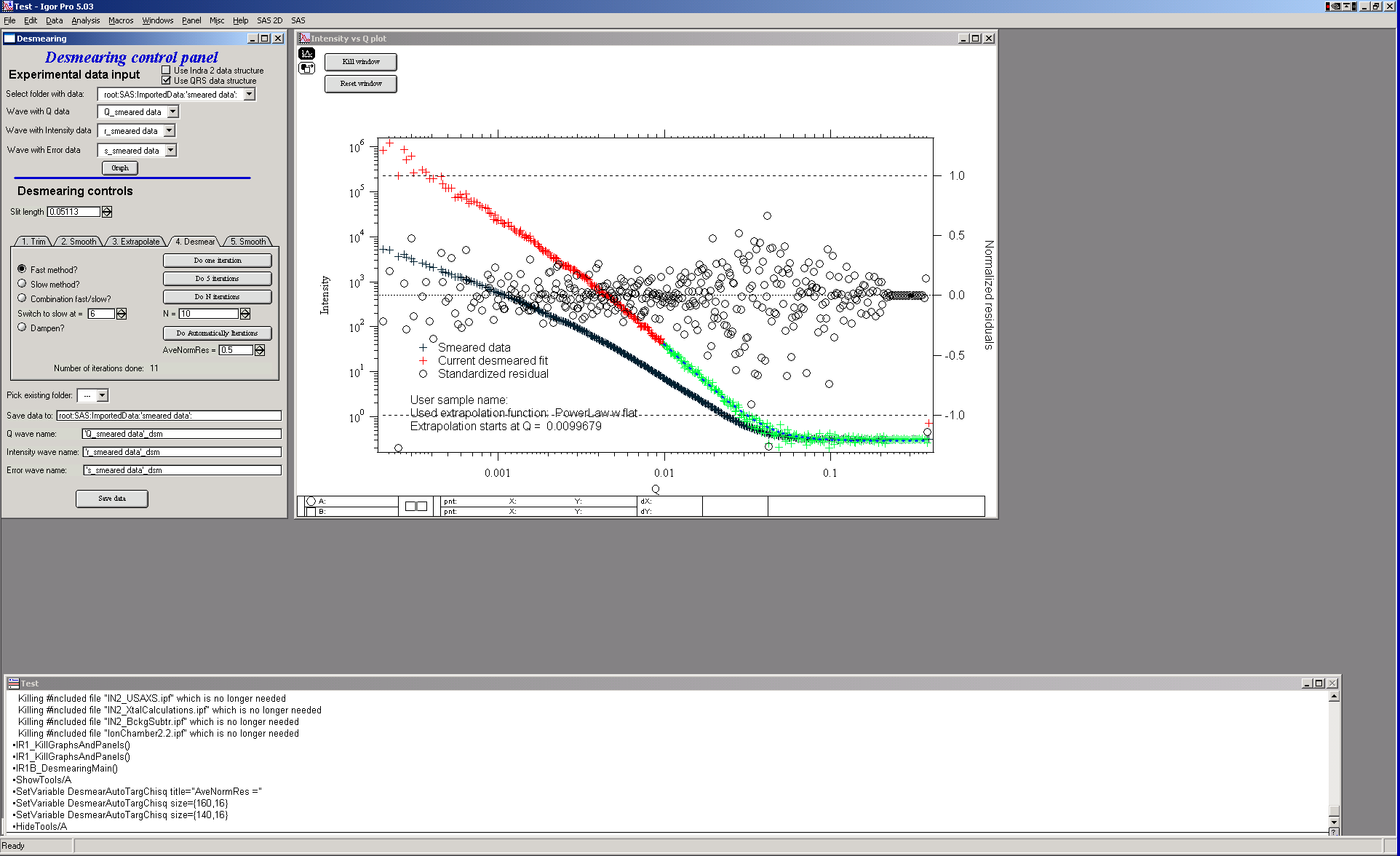
For typical data, 10–20 iterations are sufficient. Data with strong structural features may require 50 or more iterations. For this example, approximately 10 iterations produce residuals mostly within ±1.
Step 5 — Final smoothing (optional)

Smoothing at this stage is preferable to smoothing before desmearing, if it is necessary at all.
Step 6 — Save data
Use the controls at the bottom of the panel to save the desmeared data to a folder of your choice. The folder is created automatically if it does not exist.